Rules to Better Data Analytics - 3 Rules
Optimize your data analytics processes with these fundamental rules, emphasizing the importance of data cleaning and the effective use of data lakes. These guidelines will help you enhance the quality and reliability of your analytics outcomes.
Without proper data cleansing, efforts spent in analysis and modelling are often wasted. This rule covers the important steps for getting your data in good shape before the hard work begins.
Cleaning data is usually the first step in any data science project, and along with initially procuring the data, this step can take up a considerable amount of time. This rule will focus on techniques and steps required for data cleansing using Python in Azure Notebooks and using in-built functionality in the Azure Machine Learning Studio.
1. Inspect the data
Once the data has been imported, the first step is to visually and graphically inspect the data. In addition to getting a general understanding of the data, this step aims to uncover data outliers, data with formatting issues and columns where data is missing.
Using Python, data can be inspected in a tabular form by using the head and tail methods of a Pandas dataframe. These methods will output the first and last five rows of a dataframe (respectively), with an optional parameter allowing the five row default to be modified. In this step, we are looking for missing data (such as columns with NaN values) and columns where the formatting looks problematic.
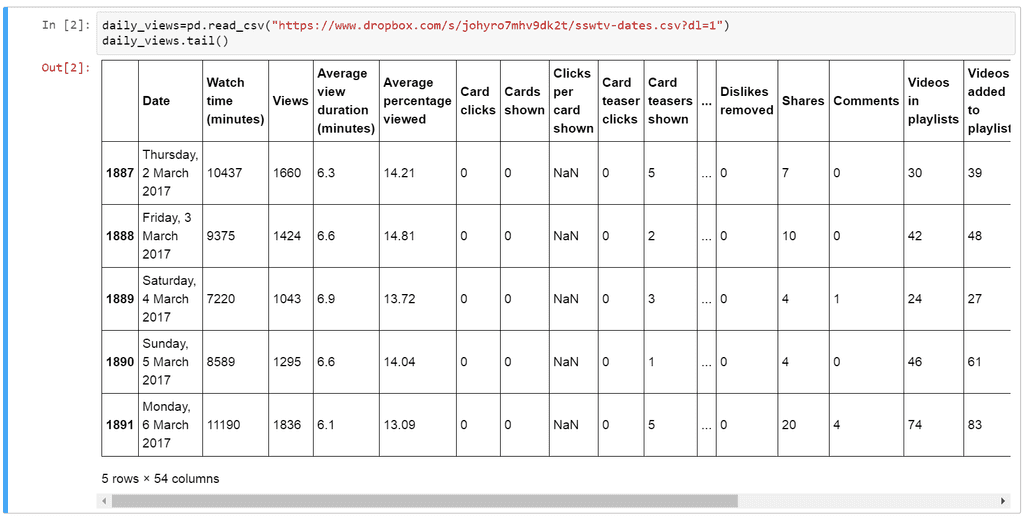
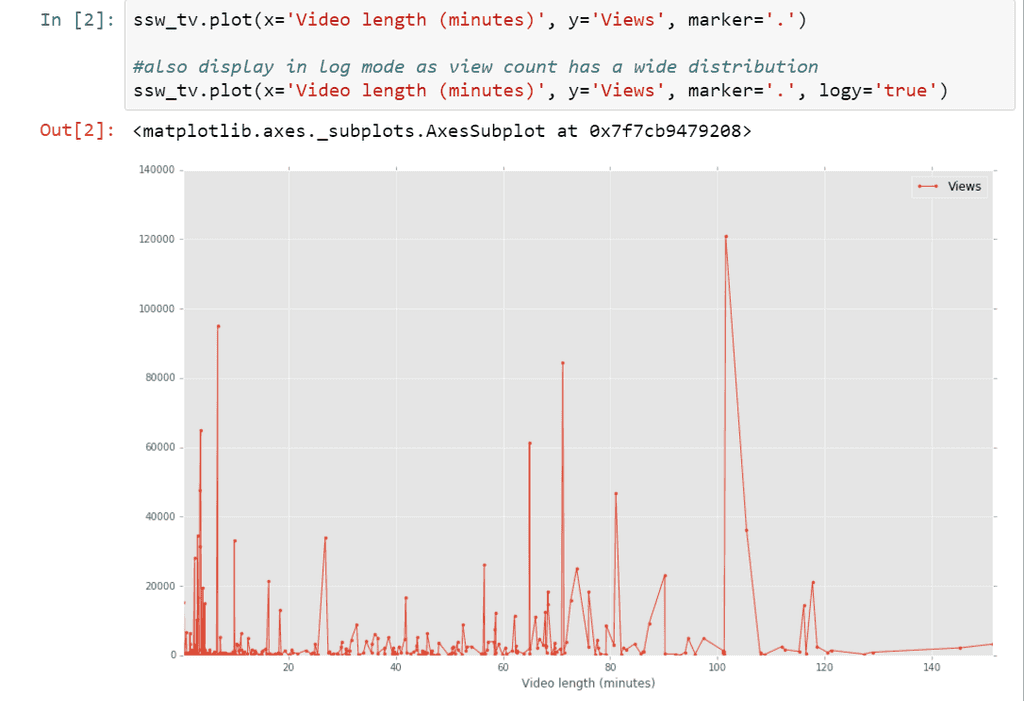
Once we have a general sense of the data and have identified columns that contain features that are of interest to the data analysis, the next step is to plot the data to get a feeling for its distribution and to check for any outliers. The 'plot' method of dataframes supports a rich variety of ways to graphically present data.
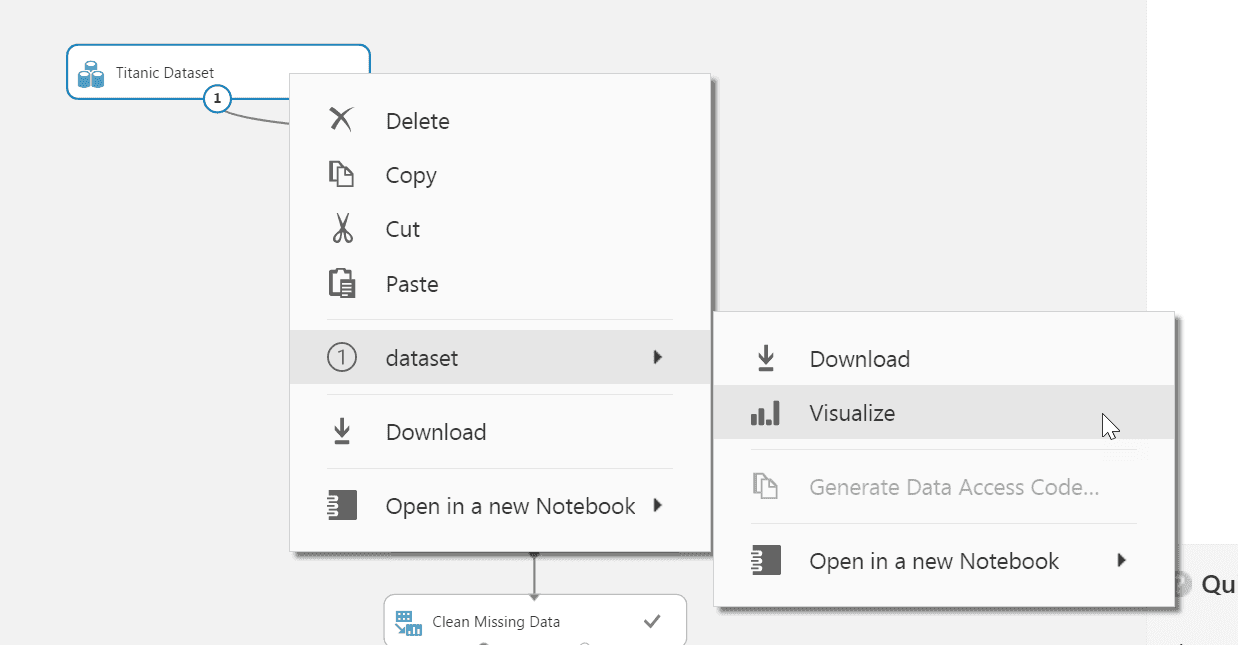
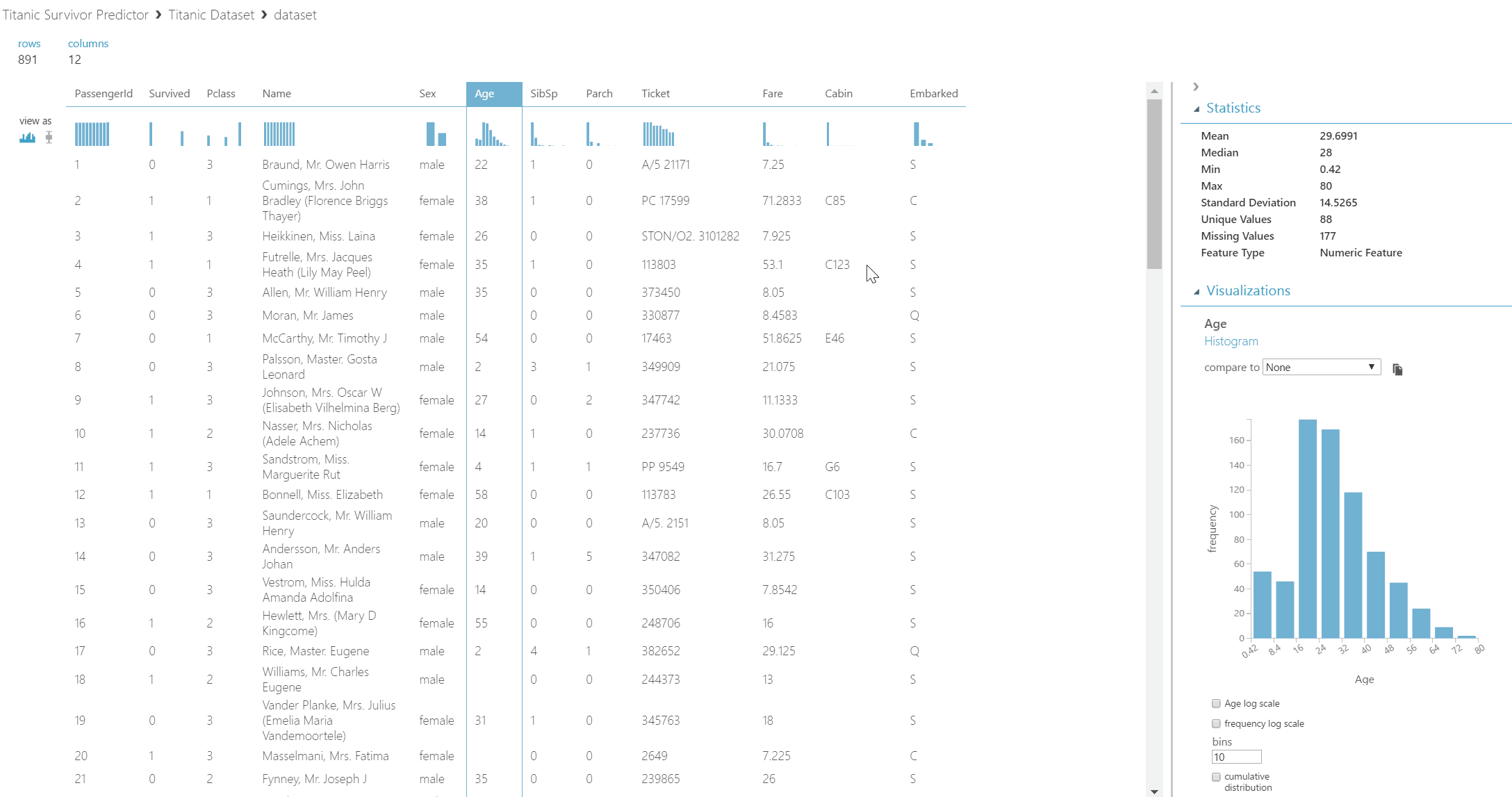
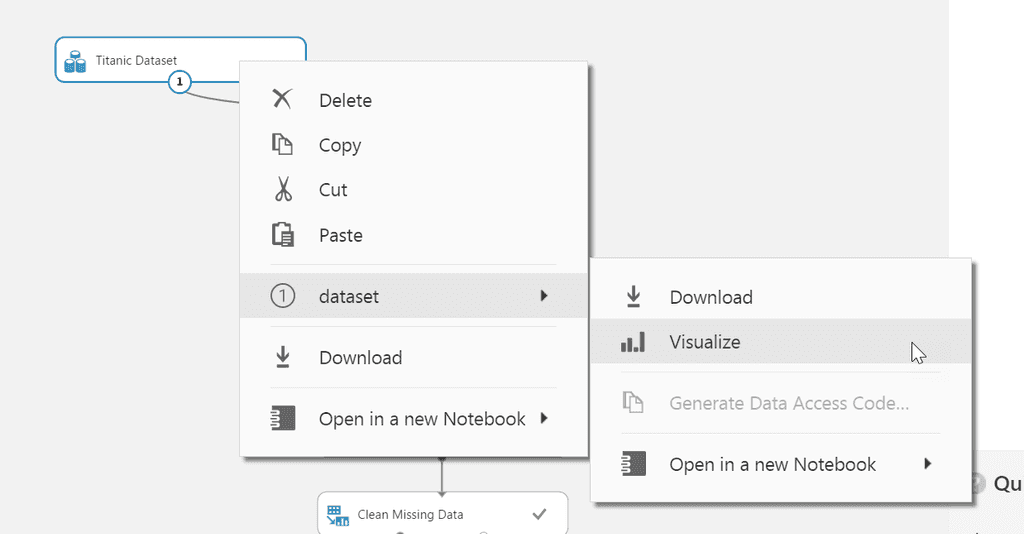
For Azure Machine Learning projects, the context menu of a dataset can be used to Visualize the data available for modelling.
 Data is displayed in a tabular form, and by selecting a column, key statistics for that column can be inspected. Two graph types are available for the data - the default histogram view and a boxplot view. Using this screen, any problems with a dataset can be readily identified.
Data is displayed in a tabular form, and by selecting a column, key statistics for that column can be inspected. Two graph types are available for the data - the default histogram view and a boxplot view. Using this screen, any problems with a dataset can be readily identified.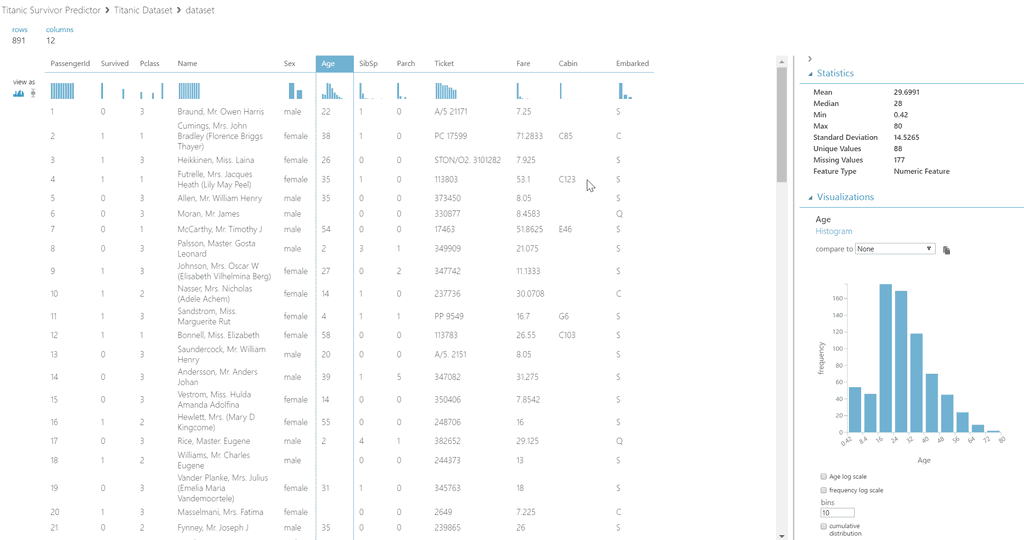
2. Decide on a strategy for dealing with missing data
Missing, incomplete or suspect data can be dealt with in one of four ways:
- The data can be left as-is if it doesn't impact any analysis or modelling activities.
- The rows with missing data can be excluded from the analysis. This is a good option if the percentage of rows with bad data is small or the missing data cannot be inferred or substituted for a sensible value. This is often the case for non-numeric fields.
- The data can be set to a default value such as zero for missing numeric fields or an empty string for text columns.
- The data can be inferred based on other values in the dataset. This can range from simple calculations like mean or medium to highly advanced formulas like Multivariate Imputation by Chained Equations (MICE). These techniques will be covered below.
Data Cleaning and Inference Techniques in Python
To exclude data from a Python dataframe, use a query expression to exclude the rows where the data is missing, and then re-assign the filtered dataframe back to the same variable. This will permanently remove the rows. This first code block creates a dataframe with a NaN value in one row:
import datetime import math import pandas as pd import numpy as np todays_date = datetime.datetime.now().date() index = pd.date_range(todays_date-datetime.timedelta(10), periods=4, freq='D') columns = ['A','B', 'C'] df = pd.DataFrame(index=index, columns=columns) df = df.fillna(0) df.set_value('2017-04-16', 'B', math.nan) #set one value in NaN df.head()Dataframe output:
A B C 2017-04-14 0 0 0 2017-04-15 0 0 0 2017-04-16 0 NaN 0 2017-04-17 0 0 0 Filtering out this row is simple using a square bracket filter expression. Here we are filtering using the Numpy isfinite method on column B to exclude the problematic row:
df = df.loc[np.isfinite(df['B'])] #filter out the NaN row df.head()Dataframe output:
A B C 2017-04-14 0 0 0 2017-04-15 0 0 0 2017-04-17 0 0 0 There is also inbuilt functionality in a dataframe to fill values by interpolation or by taking the mean value of a column. In the dataframe sample below, it is clear that this is a relationship between row values, with each row showing an increase in the values of each column, making interpolation a valid technique for filling missing data.
This first code sample great a dataframe with a number of rows with incomplete data.
df2 = pd.DataFrame({'Col1': [1, 2, np.nan, 4.8, 6],'Col2': [11, np.nan, np.nan, 16, 28]}) df2Col1 Col2 0 1.0 11.0 1 2.0 NaN 2 NaN NaN 3 4.8 16.0 4 6.0 28.0 The dataframe's inbuilt interpolate method is then used to fill the missing values. The default behaviour of interpolate is to use a linear interpolation, but a number of more advanced algorithms are also available. See the interpolation documentation for more information.
df2 = df2.interpolate() df2Col1 Col2 0 1.0 11.0 1 2.0 12.66667 2 3.4 14.33333 3 4.8 16.0 4 6.0 28.0 In this code sample, the mean value of a column is used to fill missing data.
df3 = pd.DataFrame({'Col1': [1, 2, np.nan, 4.8, 6],'Col2': [11, np.nan, np.nan, 16, 28]}) df3Col1 Col2 0 1.0 11.0 1 2.0 NaN 2 NaN NaN 3 4.8 16.0 4 6.0 28.0 df3 = df3.fillna(df3.mean()) df3Col1 Col2 0 1.0 11.0 1 2.0 18.33 2 3.45 18.33 3 4.8 16.0 4 6.0 28.0 Data Cleaning and Inference Techniques in Azure Machine Learning
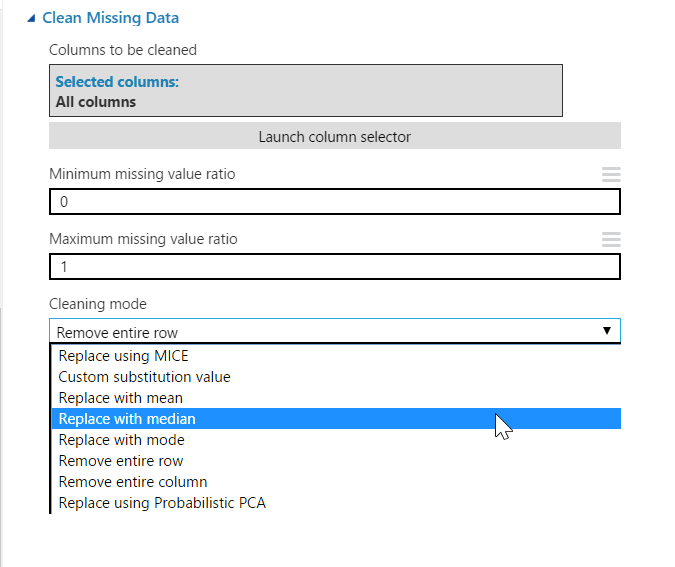
Azure ML has a specific step for cleaning missing data. The step allows the relevant columns to be selected, the minimum and maximum missing value ratios and the cleaning mode to be used. The ratios are used to control when cleaning is applied - the default values of 0 and 1 allow cleaning to be applied on all rows, but if the cleaning should only be applied in cases where 20% to 30% of the values are missing, the values would be set to 0.2 for the minimum and 0.3 for the maximum.
In addition to the simple cleaning methods such as removing the row or replacing it with the mean, much more complex methods such as Replace with MICE are available. MICE stands for Multivariate Imputation using Chained Equations, and is an inference technique that uses the distribution of values across all columns to calculate the best fitting substitution for missing values. For example, to fill in the missing values in a person's weight column, the information in other columns such as gender and age will be used to predict the best fit for the missing data. The academic paper Multiple Imputation by Chained Equations: What is it and how does it work? gives a great explanation of the workings of the MICE algorithm.
Next Steps
Once your data is clean, the next steps are to either move into in-depth analysis in a Azure Notebookor to use Azure Machine Learning to look at advanced data prediction and classification.
Imagine running a business without a clear, unified view of your data. Here's what you might face:
- Data Silos: Different departments hoard their data, making it difficult to gather holistic insights about your business.
- Inefficiency: You spend valuable time integrating data from disparate sources instead of generating insights.
- Cost Overruns: Managing multiple systems for data integration, engineering, warehousing, and business intelligence inflates your costs.
- Impaired Decision Making: Inconsistencies and lack of access to all data hinder informed decision-making.
Typically, companies managed this problem with Data Warehouses like having a SQL Server database to aggregate all their data.
These days, data lakes make it easy to consolidate all data in an unstructured manner.
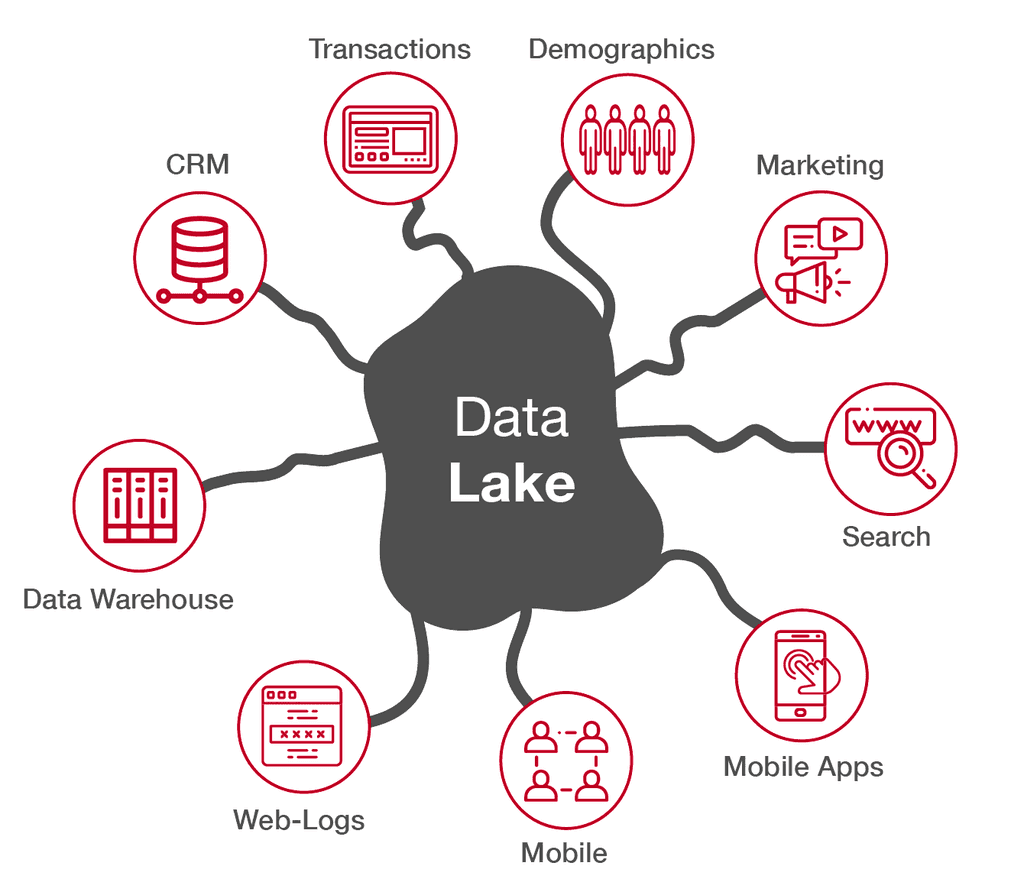
The Solution - A Data Lake
A data lake serves as a single source of truth for all company data, helping to solve the above problems.
The Power of Microsoft Fabric
Video: Microsoft Fabric: Satya Nadella at Microsoft Build 2023 (1 min)Microsoft Fabric can supercharge your data lake. Fabric integrates technologies like Azure Data Factory (for Extract, Transform, Load - ETL), Azure Synapse Analytics (for data warehousing), and Power BI (for reporting) into a single unified product, empowering data and business professionals alike to unlock the potential of their data and lay the foundation for the era of AI. 🤖
- Seamless Integration with Microsoft 365: Microsoft Fabric can turn your Microsoft 365 apps into hubs for uncovering and applying insights, making data a part of everyday work
- Unified Capacities, Reduced Costs: Microsoft Fabric unifies computing capacities across different workloads, reducing wastage and costs
- Simplified Management: It consolidates necessary data provisioning, transformation, modeling, and analysis services into one user interface, simplifying data management
- Elimination of Data Duplication: It enables easy sharing of datasets across the company, eliminating data duplication
- Smooth Transition: Existing Microsoft products like Azure Synapse Analytics, Azure Data Factory, and Azure Data Explorer connect seamlessly with Fabric, allowing a smooth transition
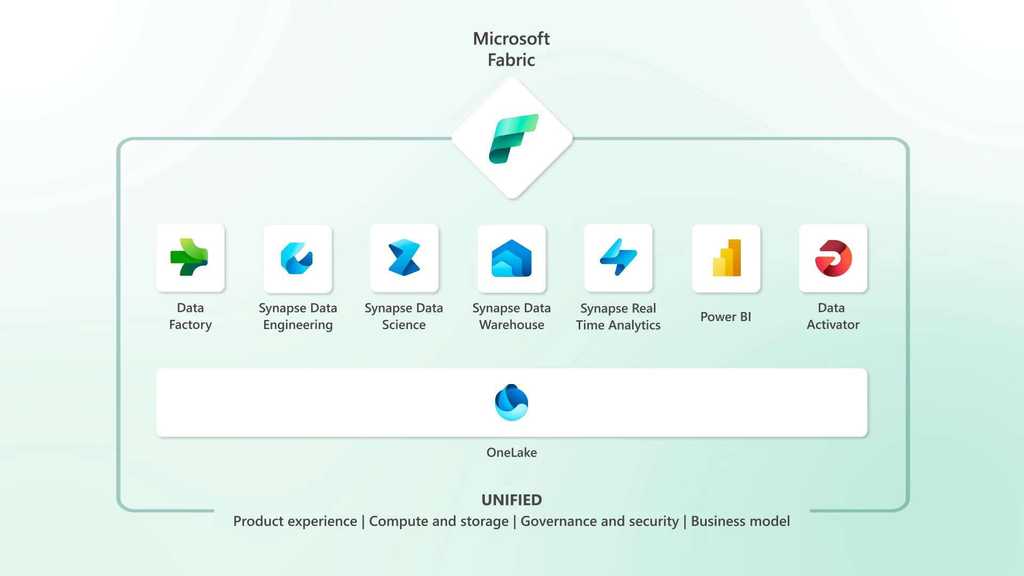
Figure: Microsoft Fabric combines all your analytics platforms into one source of truth Microsoft Fabric and AI
Microsoft Fabric integrates neatly with AI, meaning you can leverage tools like Copilot directly from the user interface.
Video: Power your AI transformation with a complete data platform: Microsoft Fabric (1 min)In conclusion, every company should have a data lake as a single source of truth, enhanced by Microsoft Fabric. It not only solves the pain of managing data in silos but also improves efficiency, reduces costs, and leads to better, data-driven decisions.
Microsoft Forms is a popular survey tool used by many organizations. When forms receive numerous responses, digesting the results becomes challenging.
Microsoft Forms offers several ways to analyze your survey responses:
Structured answers
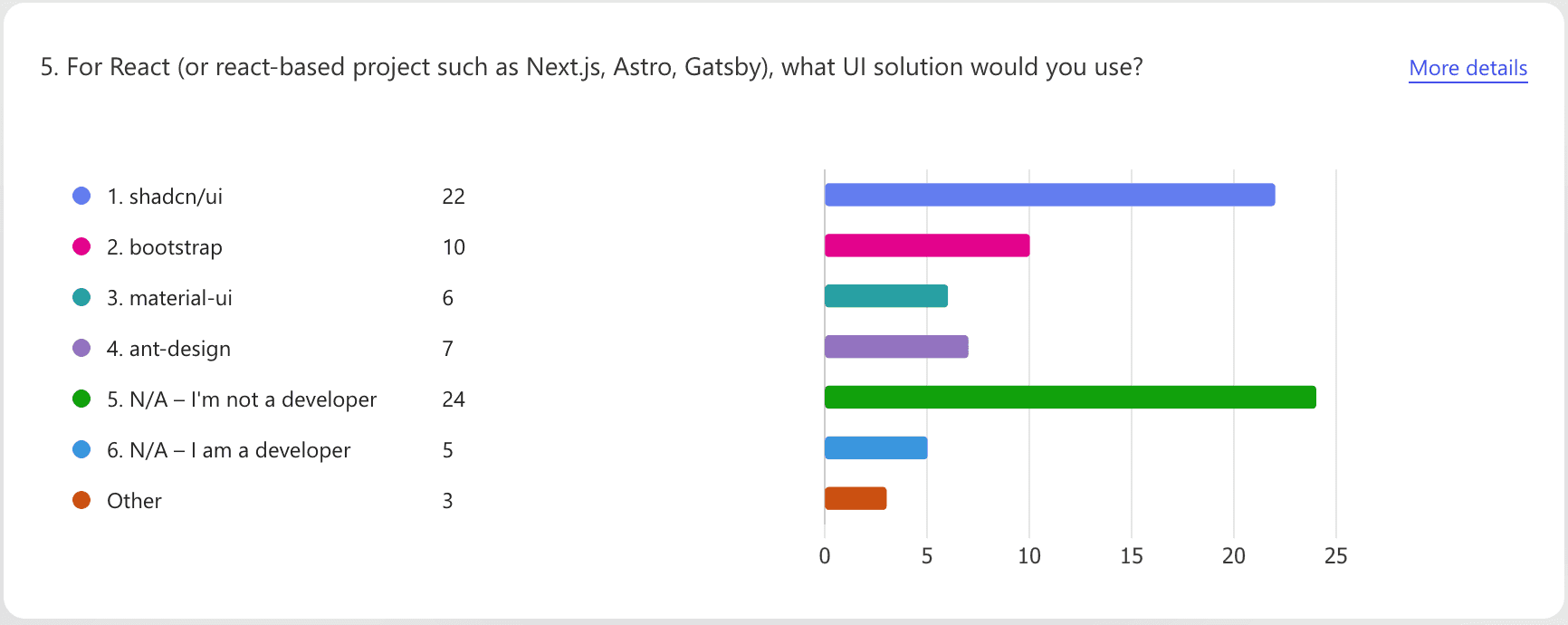
Structured (quantitative) answers include multiple choice, range, or numerical responses. Microsoft Forms excels at automatically generating graphs for these types of answers.
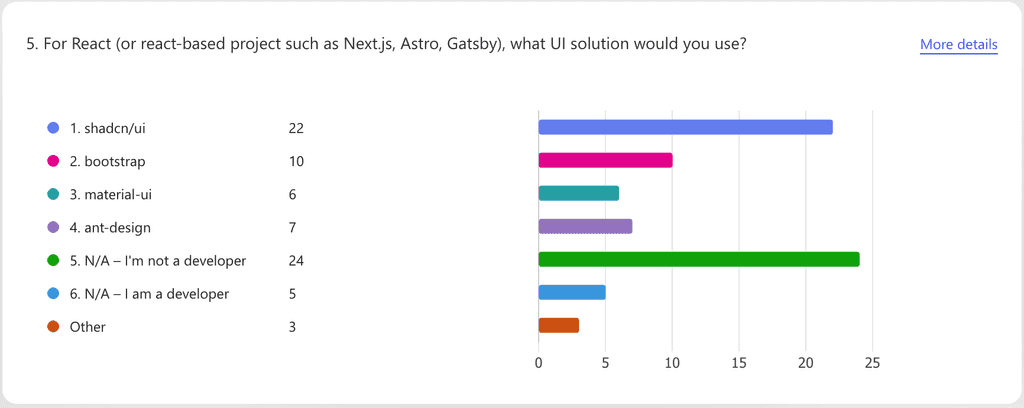
Figure: Good example - Microsoft Forms is great at displaying structured results like this Unstructured answers
Unstructured (qualitative) answers are text-based responses that allow respondents to express themselves fully, yielding more insightful survey results.
The challenge is that Microsoft Forms handles unstructured answers poorly. Your viewing options are limited to a 'word cloud' (more gimmick than analysis tool) or a basic table that contains all feedback but makes finding meaningful insights difficult.

Figure: Bad example - This tells us nothing about people's answers! This is where AI becomes invaluable for digesting unstructured data.
Which AI solution works best?
Pasting responses into ChatGPT works for small surveys (up to 20 answers), but with larger datasets, it often misses important insights due to context window limitations.
We solve this using Agentic AI with chain-of-thought reasoning. The Cursor IDE provides an accessible way to apply AI to unstructured data (or Windsurf! See our comparison table).
Cursor Agent processes CSV data line-by-line without requiring code. This approach solves the context window problem by ensuring all answers are read and annotated, producing an enhanced version of your data with key insights highlighted.
Better yet, Cursor Agent lets you interact with your data through conversation. You can ask questions like "which responses favored x?" or "are there any highly critical responses?" You can even add a sentiment column to your output, making data analysis significantly more efficient.
How to digest unstructured survey results with Cursor IDE
See how to get the most out of your Microsoft Forms results with AI.

Figure: Good example - The output of our AI survey results digest, much cleaner with a helpful 'sentiment' column! Cursor Pro is required for this.
- Export your Microsoft Forms results in
.csvformat - Create a new folder containing the
.csvfile you would like to digest - Open this new folder in Cursor IDE
- With the
.csvopen, hitctrl+L(⌘+Lfor Mac users). This opens the AI panel - Set your model, we like
gemini-2.5-prowith Thinking enabled. - Start prompting your .csv file!
We recommend Gemini 2.5 Pro as it has a massive 1 million token context window, and is highly ranked for text. But, if there are better models at the time of reading this, use them! (see the 'Text' leaderboard on LLMArena)
For example, the below prompt will read through your
.csvline by line, highlight interesting parts of each answer, and generate a sentiment for the answer, allowing you much better 'at-a-glance' survey results. We use it to create a visual stimulus for when we record our Digesting the Fat videosWe like using XML tags in our prompts. They allow LLMs to parse information more accurately, leading to higher-quality outputs. See the rule: Do you use XML to structure your AI prompts?
<context> You're a professional CSV file interpreter. Take this CSV file. It contains responses to a weekly employee survey called "Chewing the Fat". You are to compile a digest of these responses, called "Digesting the Fat". The end goal of "Digesting the Fat" is to create a video, so the digest should be in a format that presenters can read from quickly. </context> <REMEMBER> Steps - COMPLETE EACH STEP BEFORE MOVING TO THE NEXT. REMEMBER TO INCLUDE THE NAME OF WHO SAID EACH QUOTE WHEN TEXT IS QUOTED. Names can be found in the same row of where the quote is taken from in the CSV. If you are provided multiple CSV files, you should go through each of these steps for each CSV file, and add a subheading to the markdown document for each CSV file. </REMEMBER> <steps> <step-1> Create a new markdown file which does not overwrite any existing files. </step-1> <step-2> Collate ALL of the text-based responses into a table for each question that has a text response. All responses should be in this markdown file. </step-2> <step-3> Ensure that all of the text responses have been collected into a newly created markdown file. </step-3> <step-4> Once all the responses have been collected, add a new column named "Sentiment" to each of the tables in the markdown file. </step-4> <step-5> For each response in the markdown file, read it, and determine the sentiment as either (✅ Positive, ❌ Negative, 🧐 Insightful, ⚠️ Critical, 😂 Funny) </step-5> <step-6> Now, carefully read through each response in the markdown file. We are making a video with the results from this, and want to read any interesting parts of responses -- highlight in BOLD any interesting key words and phrases. Prioritise statements that seem original, critical, funny. Ignore generic phrases. </step-6> </steps> <finally> Ensure no responses have been missed, ensure you have followed each step before moving on to the next step. </finally>Code: Good example - Cursor Prompt for generating Microsoft Forms digests from
.csvLet us know in the comments how you've used the Cursor IDE for tasks like this. We think it's a game changer.
- Export your Microsoft Forms results in