Rules to Better Entity Framework - 17 Rules
Optimize your use of Entity Framework by following best practices that enhance performance and maintainability. These guidelines cover everything from efficient querying and data manipulation to leveraging migrations and in-memory providers, ensuring your application runs smoothly and effectively.
Entity Framework allows you to provide a strongly typed object framework (ORM) over your database. This helps abstract the database away allowing it to be replaced with other technologies as needed.
using (SqlConnection conn = new SqlConnection()) { conn.ConnectionString = "Data Source=(local);Initial Catalog=Northwind;Integrated Security=True"; conn.Open(); SqlCommand cmd = conn.CreateCommand(); cmd.CommandText = "SELECT * FROM Customers WHERE CompanyName LIKE '" + companyNameTextbox.Text + "%'"; bindingSource1.DataSource = cmd.ExecuteReader(); }Figure: Bad example - using ADO.NET and not strongly typed
var results = dbContext.Customers .Where(c => c.CompanyName.StartsWith(companyNameTextbox.Text)); customersBindingSource.DataSource = results; // Or even var results = dbContext.Customers .Where(c => c.CompanyName.StartsWith(companyNameTextbox.Text)) .Select(c => new { c.CompanyName, c.Phone }); customersBindingSource.DataSource = results;Figure: Good example - at least 4 good reasons below
- Making queries that are independent from specific Database engine
- Strongly typed fields - SQL tables/entities have intellisense
- More readable and less code
- It's easy to chain more operation like
OrderBy,GroupBy,FirstOrDefault,Count,Anyand many more - Developers are generally poor at writing SQL, so using code constructs makes writing queries much easier
It's expensive retrieving data from a database, as such it's important to only ask for the rows you require when getting data.
Entity Framework nicely translates the various filters like the Where method into SQL WHERE clauses. This makes it really easy to write nice readable code that is also very efficient.
List<Sale> sales = context.Sales.ToList(); foreach (var sale in sales) { if (sale.ProductId == request.ProductId) { // Do stuff } }Bad example - Retrieved all the data instead of items that matched the product id.
List<Sale> sales = context.Sales .Where(sale => sale.ProductId == Request.ProductId) .ToList(); foreach (var sale in sales) { // Do stuff }Good example - Only the data required was retrieved from the database
When you cast IQueryable to IEnumerable and then query the data from there, Entity Framework must collect the data at the point you do the cast. This can result in very significant extra database load, and extra processing on the client side.
NOTE: Using
.AsEnumerable()achieves the same effect.Counting
// All examples below will result in a SQL query similar to: // SELECT * FROM Sales // The ToList generates a list of all records client side and then counts them. int count1 = context.Sales .ToList() .Count(); // This implicitly treats the sales as an enumerable and enumerates all the items to count them. IEnumerable<Sale> sales = context.Sales; int count2 = sales.Count; // EF Core will evaluate everything before `.AsEnumerable()` and after that line, everything is in-memory. int count3 = context.Sales .AsEnumerable() .Count(); // This is the most common source of `IEnumerable` casting which can cause significant performance issues. public IEnumerable<Sale> GetSales() => context.Sales; // The code on the first glance looks alright but in fact it fetches the entire table from SQL Server // because it receives the query as `IEnumerable` before running `.Count()`. int count4 = GetSales().Count();Bad example - All these examples read the entire table instead of just returning the count from the database.
// All of the examples below will result in SQL query: // SELECT COUNT(*) FROM Sales int count1 = context.Sales.Count(); IQueryable<Sale> query = _context.Sales; int count2 = query.Count(); public IQueryable<Sale> GetSales() => context.Sales; int count3 = GetSales().Count();Good example - Only the count is returned by the query
Where
// All of the examples below will result in a SQL query like: // SELECT * FROM Sales List<Sale> sales1 = context.Sales .AsEnumerable() .Where(x => x.Id == 5) .ToList(); private IEnumerable<Sale> Sales { get { return context.Sales; } } List<Sale> sales2 = Sales .Where(x => x.Id == 5) .ToList();Bad example - The whole table is returned from the database and then discarded in code.
// All Examples will result in a SQL query like: // SELECT * FROM Sales WHERE Id = 5 List<Sale> sales1 = context.Sales .Where(x => x.Id == 5) .ToList(); private IQueryable<Sale> Sales { get { return context.Sales; } } List<Sale> sales2 = Sales .Where(x => x.Id == 5) .ToList();Good example - Filtering is done on the database before returning data.
One of EF Core's best features is the fact it tracks any changes you make to entities after you retrieve them. However this comes with a cost, if the data is only being read and the returned entities will never be modified then you can use the AsNoTracking method to inform EF Core not to bother tracking changes.
This results in fairly significant memory and CPU improvements on the client side.
return context.Sales.AsNoTracking().Where(x => x.Id == 5).ToList();Figure: Using AsNoTracking to save CPU and memory for a read only query
When retrieving data it's much more efficient to only collect the data you need. It saves computation and IO on the database and also saves memory and CPU on the calling side.
IEnumerable<string> GetProductGuids(string category) { IEnumerable<Product> products = context.Products .Where(x => x.Category == category) .ToList(); return products.Select(x => x.ProductGuid); }Figure: Bad example - Retrieved the whole product record when we only needed 1 property
IEnumerable<string> GetProductGuids(string category) { IEnumerable<string> productGuids = context.Products .Where(x => x.Category == category) .Select(x => x.ProductGuid) .ToList(); return productGuids; }Figure: Good example - Retrieved only the required property.
The Update method on an entity in EF Core marks all of its fields as dirty. This will result in all the fields being written back to the database.
Writing the entire record to the database can cause locking issues in the database server if there are foreign key relationships involving the entity being modified.
var entity = context .Products .FirstOrDefault(item => item.ProductID == id); if (entity != null) { entity.Name = "New name"; context.Products.Update(entity); context.SaveChanges(); }Figure: Bad example - The whole record is written back to the database.
var entity = context .Products .FirstOrDefault(item => item.ProductID == id); if (entity != null) { entity.Name = "New name"; context.SaveChanges(); }Figure: Good example - Only the modified fields are written back to the database.
Often developers will include all the related entities in a query to help with debugging. Always remember to take these out. They cause excessive database load.
If you need the related entities, then that is what Include is for.
var query = _dbContext .Sales .Include(x => x.SalesPerson);Figure: Bad example - Retrieved the sales records and the salesperson, even though we don't intend to use the salesperson record.
var query = _dbContext .Sales;Figure: Good example - Retrieved only the sales records themselves
Pagination can be expensive if all the pages are retrieved from the database before grabbing the relevant page. It's much more efficient to get only the page number requested back from the database.
var query = context .Sales .AsNoTracking() .Where(x => x.SalesPersonId == salesPersonId); var result = await query.ToListAsync(); int count = result.Count; result = result .Skip(page * pageSize) .Take(pageSize); return (count, result);Figure: Bad example - Reads all the data from the database, counts the records and filters down to the page
var query = context .Sales .AsNoTracking() .Where(x => x.SalesPersonId == salesPersonId); int count = await query.CountAsync(); query = query .Skip(page * pageSize) .Take(pageSize); var result = await query.ToListAsync(); return (count, result);Figure: Good example - Reads only the count and 1 page of data from the database
TagWith adds comments to the generated SQL. This makes it easier to identify queries when they run on the database.
This is very useful when debugging issues as there are often multiple pieces of code that generate similar statements and as such it's hard to identify what is executing particular queries.
var list = await context .Sales .TagWith("Get All Sales") .ToListAsync(ct);Figure: Code to add tagging
-- Get All Sales select * from salesFigure: SQL generated by the above code
To avoid embarrassing failures in Production, it is important to ensure that your development systems are as similar as possible to what's expected in Production.
Modifying and querying database tables is very dependent on the amount of data in the table. Often developers will run their code in a database without sufficient data in the tables and therefore the queries are nice and fast. The problem is when there's millions of transactions already in the database, all the queries turn out to be far too slow.
So it is an important part of the development process to seed your development databases with a reasonable amount of representative data.
Benchmarking your system's performance is important. This is making sure you have information on how your system performs with a known set of data and load.
Benchmarking allows you to then optimize code and actually know that things improved.
There are plenty of good benchmarking tools for .Net solutions.
- BenchmarkDotNet is good because it monitors memory consumption and timings.
- Bombardier is a simple CLI load testing tool.
- NBomber is good for automating load tests
- RedLine13 uses AWS spot instances to provide really cheap enormous scale for load testing
Try these out and there are more available. Which one suits will depend on your solution and what information you want.
Databases are slow at doing bulk updates. It's generally significantly faster to break bulk processing down into manageable chunks. It also avoids other database users experiencing significant blocking issues.
Linq include the Chunk method to make this process nice and easy.
var productIds = context.ProductIds; foreach(var chunk in productIds.Chunk(10)) { // Do stuff }Raw SQL comes with risks but sometimes it is the best solution.
Using raw SQL involves taking care of SQL injection and other risks, however there are a number of situations where it may be the best solution.
The most obvious is a SQL UPDATE statement which updates a large number of rows.
await context.Database.ExecuteSqlInterpolatedAsync($"UPDATE Employees SET Active = {activeState}", ct);Good example - Updating a large number of rows quickly with SQL
Most enterprise applications require a database to store data. Once you have a database you need a way to manage the schema.
Entity Framework Code First Migrations allow you to update a database schema rather than recreate it from scratch. This is useful when you have a production database that you want to keep, but you want to make changes to the schema.
Database Schema Management Options
Managing database schemas effectively is crucial for the smooth operation and evolution of software applications. For more options to manage database schemas, see the best tools for updating database schemas.
Configuring Entity Framework Code First Migrations
The following assumes you have an existing project with a database context, entities, and have already installed the EF Core nuget packages.
- Install EF Core Tools
dotnet new tool-manifest dotnet tool install dotnet-ef- Enable migrations
dotnet ef migrations add InitialCreateThis will create a migration file in your project. This file contains the code to create the database schema.
// Example of EF Core Migration in a .NET 8 project public partial class AddUserTable : Migration { protected override void Up(MigrationBuilder migrationBuilder) { migrationBuilder.CreateTable( name: "Users", columns: table => new { Id = table.Column<int>(nullable: false) .Annotation("SqlServer:Identity", "1, 1"), Name = table.Column<string>(nullable: true) }, constraints: table => { table.PrimaryKey("PK_Users", x => x.Id); }); } protected override void Down(MigrationBuilder migrationBuilder) { migrationBuilder.DropTable( name: "Users"); } }- Update database
dotnet ef database updateUsing Rider
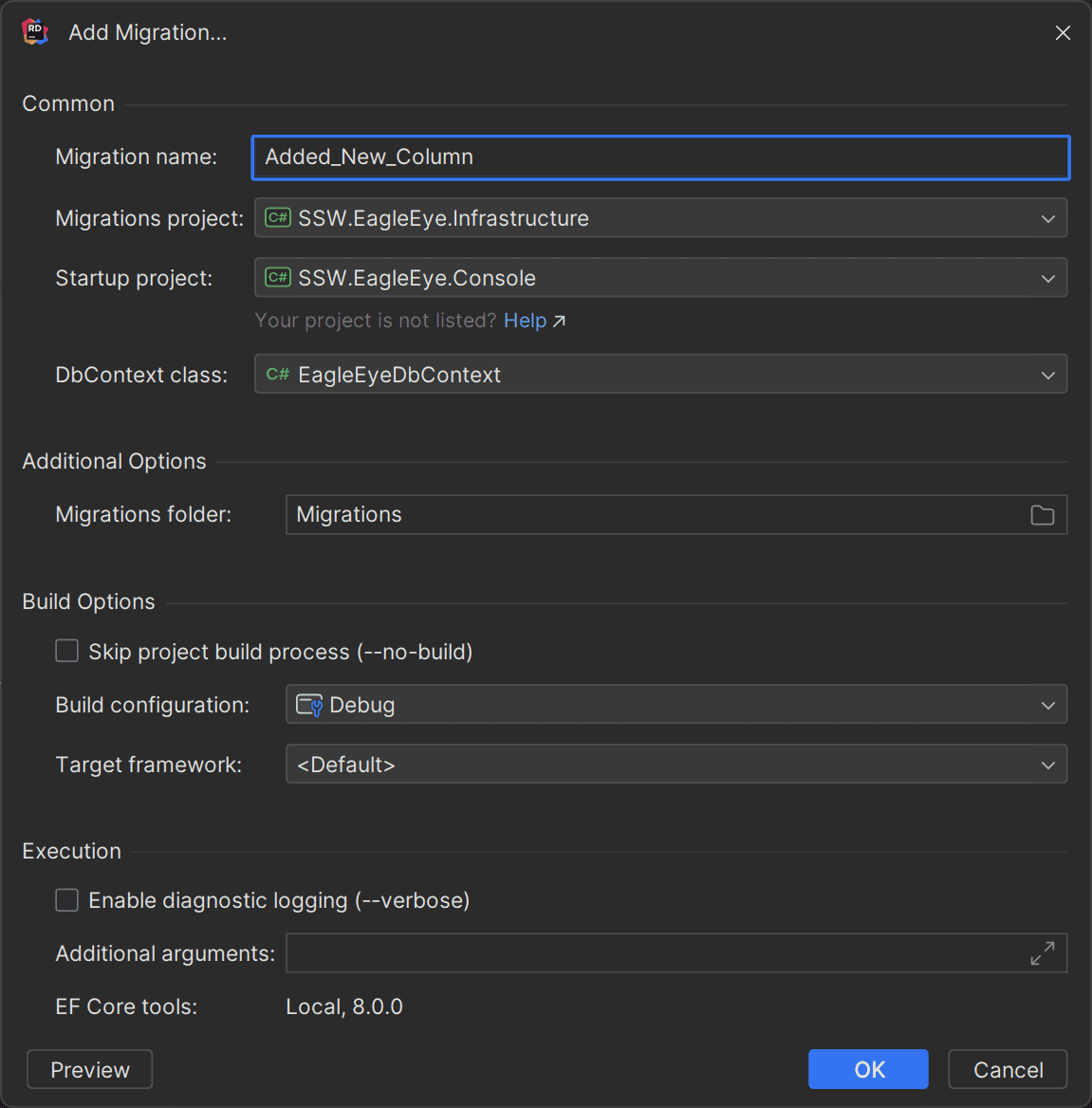
If you struggle to remember the commands above, Rider has a great UI that makes creating migrations easy. This is especially useful when you have different projects for both startup and migrations.
Rider - EF Core Migrations Executing Entity Framework Code First Migrations
Once you have some migration, you'll then need to decide when these get run. Naively, developers will often run migrations during program start-up, but this is not recommended. Doing so can cause issues in a web farm environment, as well as cause unnecessary delays during start-up.
var dbContext = scope.ServiceProvider.GetRequiredService<EagleEyeDbContext>(); await dbContext.Database.MigrateAsync();Figure: Bad example - Running migrations manually during startup in
program.csEntity Framework Migration Bundles
A place to run migrations is during your CICD deployment pipeline.
dotnet ef migrations bundle --self-contained --force .\efbundle.exe --connection {$ENVVARWITHCONNECTION}Figure: Good example - Creating and executing a migration bundle during a CICD pipeline
If an
appsettings.jsonfile can be found the connection string can be automatically picked up.When testing code that depends on Entity Framework Core, the challenge often lies in how to effectively mock out the database access. This is crucial for focusing tests on the functionality surrounding the DB access rather than the database interactions themselves. The EF Core In-Memory provider is a tool designed to address this need.
Common Pitfalls in Mocking
Trying to Mock
DbContextAttempting to mock the entire
DbContextis a common mistake. This approach typically leads to complex and fragile test setups, making the tests hard to understand and maintain.var mockContext = new Mock<ApplicationDbContext>(); // Adding further mock setups...Figure: Bad Example - Mocking the entire DbContext is overly complex and error-prone.
Trying to Mock
DbSetSimilarly, mocking
DbSetentities often results in tests that don't accurately reflect the behavior of the database, leading to unreliable test outcomes.var mockSet = new Mock<DbSet<MyEntity>>(); // Configuring mockSet behaviors...Figure: Bad Example - Mocking DbSet entities fails to mimic real database interactions effectively.
Good Practice: Using DbContext with In-Memory Provider
Instead of extensive mocking, using
DbContextwith the EF Core In-Memory provider simplifies the setup and reduces the need for mocks. This approach enables more realistic testing of database interactions.var options = new DbContextOptionsBuilder<ApplicationDbContext>() .UseInMemoryDatabase(Guid.NewGuid().ToString()) .Options; var dbContext = new ApplicationDbContext(options);Figure: Good Example - Using DbContext with an EF Core In-Memory provider for simpler and more effective testing.
Caveat: Limitations of In-Memory Testing
While the EF Core In-Memory provider is useful for isolating unit tests, it's important to recognize its limitations:
- Behavioral Differences: It doesn't emulate all aspects of a SQL Server provider, such as certain constraints or transaction behaviors.
- Not Suitable for Query-focused Tests: For tests that focus on EF queries, more realistic results can be achieved through integration tests with an actual database.
Checkout JK's EF Core Testing Repository for comprehensive examples and advanced scenarios in EF Core testing.
Some older projects .NET Framework project will have EDMX instead of modern DbContext first introduced in Entity Framework 4.1, which first introduced DbContext and Code-First approach back in 2012, replacing the ObjectContext that EDMX used for Database-First approach.
In this rule, we’ll use ObjectContext and Entities interchangeably. ObjectContext is the base class that is used by the generated class, which will generally end with Entities (e.g. DataEntities).
The rule is focusing on .NET 8+ as the support for .NET Framework projects and Nuget was added back, which makes a staged migration a lot more feasible. Most, if not all, are still applicable for .NET 7 as well.
Strategies
There are a few strategies regarding the migration from a full rewrite with to a more in-place migration. Depending on the scale and complexity of the project. This rule will describe an approach that balances the code we need to rewrite and modernisation.
The focus is to minimise the amount of time no deployments are made due to migration.
The strategy in this rules will include:
- Abstract existing
ObjectContext/Entitiesclass with a customIDbContextinterface (e.g.ITenantDbContext) -
Scaffold DB
- EF Core Power Tools
- If the tool fails, use When to use EF Core 3.1 or EF Core 8+ CLI for scaffolding. EF Core 3.1 can better deal with older DB schemes than EF Core 8+
-
Implement interface from step 1 and refactor entities
- Review entities, adjust generated code and update
DbContext.OnConfiguring - Replace
ObjectSet<T>withDbSet<T> - Make any other necessary refactors
- Nullables might be treated differently
- Some properties will be a different type and you'll need to fix the mapping
- Lazy loading can be an issue. Fix it with eager loading.
-
When upgrading to EF Core 3.1, group by and some other features are not supported
- Use
.AsEnumerable(), use raw SQL or change how the query works - Add a TechDebt comment and PBI - Do you know the importance of paying back Technical Debt?
- Use
- Review entities, adjust generated code and update
-
Update namespaces (for Entities, EF Core namespaces and removing legacy namespaces)
- Remove
System.Data.Entitynamespace in all files using EF Core 3.1 (otherwise, you'll get odd Linq exceptions) - Add
Microsoft.EntityFrameworkCorenamespace
- Remove
-
Update dependency injection
- Use modern
.AddDbContext()or.AddDbContextPool()
- Use modern
-
Update migration strategy (from DB-first to Code-first)
- Use EF Core CLI instead of DbUp
- Remove EDMX completely (can be done sooner if migration is done in 1 go rather than in steps)
- Optional: Upgrade to .NET 8+ (if on .NET Framework or .NET Core 3.1)
- Optional: Upgrade to EF Core 8+ (if EF Core 3.1 path was necessary)
-
Test, test, test...
- Going from EDMX to EF Core 3.1 or later is a significant modernization with many under-the-hood changes
-
Common issues are:
- Lazy loading
- Group by (if in EF Core 3.1)
- Unsupported queries (code that was secretly running on .NET side instead of SQL Server)
- Performance issues because of highly complicated queries
- Incorrect results from EF Core query
Steps 6 and 7 are required when upgrading from .NET Framework to .NET 8 and the solution is too complex to do the migration in one go. For simple projects, if EDMX is the only major blocking issue, they should go straight to .NET 8 and EF Core 8.
NOTE: With some smart abstraction strategies, it is possible to do steps 3 - 5 while still having a working application. It is only recommended for experienced developers in architecture and how EF operates to avoid bugs related to running 2 EF tracking systems. This will impact EF internal caching and saving changes.
In this rule, we'll only cover abstracting access to
ObjectContextwith a customIDbContextand how to scaffold the DB. The rest of the steps require in-depth code review and may differ greatly between projects.1. Abstracting access to ObjectContext/Entities
Before starting, it’s important to note that ObjectContext and EDMX are no longer supported and we need to do a full rewrite of the data layer. You can wrap ObjectContext with an interface that looks like modern DbContext, as most commonly used methods are identical.
The wrapper below not only allows us to use ObjectContext in a cleaner way (see Rules to Better Clean Architecture) but also allows us to better manage the differences between ObjectContext and DbContext without needing to refactor the business logic.
using System.Data.Entity.Core.Objects; public interface ITenantDbContext { ObjectSet<Client> Clients { get; } int SaveChanges(); Task<int> SaveChangesAsync(CancellationToken ct = default); } /// <summary> /// Implement DbContext as internal, so that external libraries cannot access it directly. /// Expose functionality via interfaces instead. /// </summary> internal class TenantDbContext : ITenantDbContext { private readonly DataEntities _entities; public TenantDbContext(DataEntities entities) { _entities = entities; } public ObjectSet<Client> Clients => _entities.Clients; public int SaveChanges() => _entities.SaveChanges(); public Task<int> SaveChangesAsync(CancellationToken ct = default) => _entities.SaveChangesAsync(ct); }Figure: Abstracting ObjectEntities behind an interface and using an interface to reduce the amount of issues while migrating.
NOTE: The changes made in this section are still compatible with .NET Framework, allowing us to deliver value to the clients while the above changes are made.
2. Scaffolding the DB
Now that we abstracted access to the data, it's time to scaffold the DB. The easiest way to do this is by using EF Core Power Tools.
- Right click on the project | EF Core power Tools | Reverse Engineer

Figure: Select reverse engineer tool - Choose your data connection and EF Core version

Figure: Data Connection - Choose your database objects (tables, views, stored procedures, etc.)
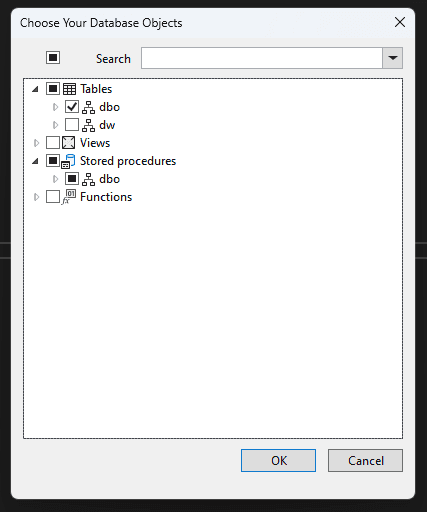
Figure: Database Objects -
Choose the settings for your project
- Recommended: Use DataAnnotation attributes to configure the model to reduce a lot of lines of code in DbContext
- Optional: Install the EF Core provider package in the project if you have not yet done that
- Optional: Use table and column names directly from the database if your existing code relies on that naming scheme

Figure: Settings for project - Code will generate under the path we decided (EntityTypes path). In this case, it's
Persistencefolder
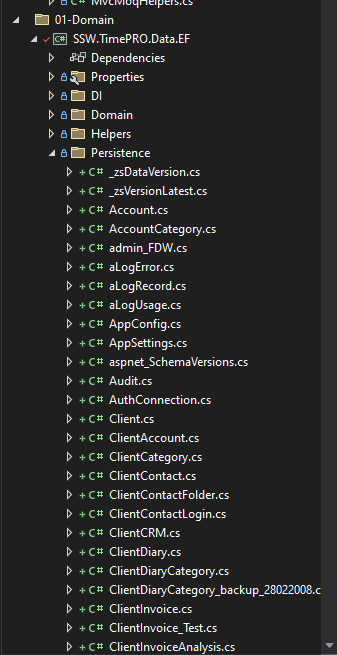
Figure: Settings for project - A
DbContextclass will be auto-generated by EF Core Power Tools

Figure: Settings for project Resources
- How to migrate to EF Core 3.1 video - https://learn.microsoft.com/en-us/shows/on-net/migrating-edmx-projects-to-entity-framework-core
- Official porting docs to EF Core 3.1 - https://learn.microsoft.com/en-us/ef/efcore-and-ef6/porting/port-edmx?WT.mc_id=DP-MVP-33518
Alternative
EF Core 3.1 EDMX - Walk-through: Using an Entity Framework 6 EDMX file with .NET Core | ErikEJ's blog
While the above blog is supposedly working in EF Core 3.1, there is no information on whether that is true for .NET 8. It would still require a lot of migrations.
Limitations:
- EDMX is not supported in .NET Standard or .NET or any other SDK-style projects (required for .NET migrations)
- Requires a dedicated .NET Framework project that is not yet upgraded to an SDK-style project to generate and update EDMX, models and ObjectContext
- EF6 and EDMX are out of support
- Built for EF Core 3.1 which is out of support
- Unknown if it works on .NET 8 even with legacy .NET Framework support
- ObjectContext (the core of EDMX) was slowly phasing out, being replaced by DbContext in 2012
- Abstract existing